Приведіть свої CARS & BS у порядок перед міграцією. 😂
Ця проста мнемоніка охоплює шість основних джерел даних для створення повного списку URL:
- Crawl (Сканування)
- Analytics (Аналітика)
- Redirects (Редиректи) (існуючі)
- Sitemap (Карта сайту)
- Backlinks (Зворотні посилання)
- Search Console (Консоль пошуку)
Зберіть з усіх шести джерел, і ви не пропустите жодної важливої URL-адреси.
| Завдання зі збору URL |
Мета |
| Сканування домену для HTML URL |
Виявлення всіх активних сторінок |
| Категоризація за кодом статусу |
Визначення потреб у редиректах |
| Збір URL із зворотними посиланнями |
Збереження SEO-капіталу |
| Сканування XML-карти сайту |
Захоплення заявлених важливих сторінок |
| Експорт даних Search Console |
Пошук проіндексованих URL |
| Збір URL з аналітики |
Визначення сторінок, що генерують трафік |
| Аудит існуючих таблиць редиректів |
Запобігання ланцюжкам редиректів |
| Об’єднання всіх наборів даних |
Створення вичерпного списку редиректів |
Які набори даних я повинен використовувати для складання вичерпних списків URL?
Найкраща практика
Успішна міграція сайту вимагає збору URL з декількох джерел, щоб не пропустити жодної важливої сторінки. Покладання на одне джерело призведе до прогалин у покритті редиректами.
Основні джерела даних
| Джерело |
Що воно захоплює |
| Сканування домену |
Всі доступні для виявлення HTML URL |
| XML-карта сайту |
URL, які ви заявили як важливі |
| Google Search Console |
URL, про які знає Google |
| Аналітика |
URL з фактичним трафіком |
| Інструменти зворотних посилань |
URL з зовнішніми посиланнями |
| Існуючі таблиці редиректів |
Поточні зіставлення редиректів |
Підхід з декількома джерелами
Кожне джерело захоплює URL, які інші можуть пропустити:
- Сканери пропускають сторінки-сироти, які не пов’язані внутрішньо
- Карти сайту можуть бути застарілими або неповними
- Search Console показує лише проіндексовані URL
- Аналітика пропускає сторінки з нульовим трафіком
- Інструменти зворотних посилань фокусуються на сторінках з зовнішніми посиланнями
Збирайте з усіх доступних джерел, а потім видаляйте дублікати. Набагато краще мати надлишкові дані, ніж пропустити високоцінну URL-адресу, яка втратить трафік або SEO-капітал після міграції.
Як мені просканувати домен для збору HTML URL?
Критичний перший крок
Почніть зі сканування всього вашого домену за допомогою такого інструменту, як Screaming Frog, Sitebulb або подібних веб-сканерів. Це виявляє всі HTML-сторінки, які пов’язані всередині вашої структури сайту.
Конфігурація сканування
Рекомендовані налаштування:
- Глибина сканування: Необмежена (або достатньо висока, щоб охопити всі сторінки)
- Поважати robots.txt: Вимкнено для цілей міграції (вам потрібні ВСІ URL)
- Слідувати внутрішнім посиланням: Увімкнено
- Сканувати за межами початкової папки: Вимкнено (залишайтеся на своєму домені)
- Зберігати HTML: Опціонально, але корисно для порівняння контенту
Що витягувати
Експортуйте наступне зі свого сканування:
URL Address
Status Code
Indexability
Canonical URL
Meta Robots
Title
Поради для обробки великих сайтів
Для сайтів з понад 100 000 URL:
- Сегментація за підкаталогами: Скануйте
/blog/, /products/, /pages/ окремо
- Використовуйте режим списку: Надавайте відомі URL безпосередньо замість виявлення
- Збільште виділення пам’яті: Screaming Frog може потребувати 8 ГБ+ оперативної пам’яті
- Запускайте на ніч: Великі сканування можуть тривати годинами
⚠️ Скануйте живий сайт
Завжди скануйте свій поточний продакшн-сайт до початку міграції. Сканування тестового або розробницького середовища пропустить URL, які існують лише в продакшні.
Проведіть сканування принаймні двічі: один раз на початку планування міграції та один раз безпосередньо перед запуском. URL змінюються під час розробки, і вам потрібні найактуальніші дані.
Як мені категоризувати URL за кодом статусу?
Суттєва організація
Після сканування категоризуйте всі виявлені URL за їх HTTP-кодом статусу. Кожна категорія вимагає різного підходу у вашій стратегії редиректів.
Категорії кодів статусу
200 OK URL: Ваш основний список джерел редиректів
| Підкатегорія |
Опис |
Дія |
| Індексовані |
Можуть з’явитися в результатах пошуку |
Високопріоритетні редиректи |
| Неіндексовані |
Заблоковані від індексації |
Оцініть потребу в редиректі |
| Канонізовані |
Вказують на іншу URL |
Переспрямувати на канонічну ціль |
| NoIndex |
Присутній тег meta noindex |
Низькопріоритетні редиректи |
| UTM-параметри |
URL відстеження маркетингу |
Зазвичай виключаються з редиректів |
| Параметри фільтрів |
URL фасетної навігації |
Зазвичай виключаються з редиректів |
301/302 Redirect URL: Вже перенаправляють
- Документуйте існуючі напрямки редиректів
- Переконайтеся, що нові редиректи вказують на кінцеві пункти призначення
- Уникайте створення ланцюжків редиректів
404 Not Found URL: Зламані, але потенційно важливі
- Перевірте зворотні посилання, що вказують на ці URL
- Перегляньте Search Console на предмет проіндексованих 404
- Можуть потребувати редиректів, якщо мають SEO-цінність
Створіть окремі вкладки електронної таблиці або файли для кожної категорії кодів статусу. Це полегшує застосування різних стратегій редиректів до кожної групи.
Чи повинен я включати URL з кодами статусу, відмінними від 200?
Так: критично для повного покриття
Багато міграційних проєктів фокусуються лише на сторінках зі статусом 200, але URL з 301/302 та 404 однаково важливі для збереження SEO-капіталу та користувацького досвіду.
Чому важливі 301/302 URL
Існуючі редиректи представляють URL, які колись мали цінність:
- Зовнішні сайти можуть все ще посилатися на старі URL
- Пошукові системи можуть мати проіндексовані старі URL
- Користувачі могли додати старі URL до закладок
Якщо ви ігноруєте існуючі редиректи:
Старий URL → Поточний редирект → Новий сайт (зламаний)
При правильній обробці:
Старий URL → Новий сайт (прямий)
Чому важливі 404 URL
Статус 404 не означає, що URL безцінна:
| Сценарій 404 |
Потреба в редиректі |
| Має зворотні посилання з зовнішніх сайтів |
Так: зберегти капітал посилань |
| З’являється в Search Console |
Так: Google знає про це |
| Показує трафік в аналітиці |
Так: користувачі шукають це |
| Нещодавно видалений контент |
Можливо: оцініть релевантність |
| Ніколи не мав трафіку або посилань |
Ні: безпечно ігнорувати |
Збір даних 404
Експортуйте 404 з:
- Результатів сканування Screaming Frog
- Звіту про покриття Google Search Console
- Логів доступу до сервера
- Аналітики (сторінки з нульовими переглядами, але сесіями)
⚠️ Не перенаправляйте все
Не кожна 404 потребує редиректу. Зосередьтеся на 404, які мають зворотні посилання, пошукові враження або представляють контент, який перемістився, а не контент, який був навмисно видалений.
Перехресно перевірте свій список 404 з даними Ahrefs або Search Console. Надавайте пріоритет редиректам для 404 URL, які мають зовнішні зворотні посилання або недавні пошукові враження.
Які варіації URL я повинен врахувати?
Поширена пастка міграції
До тієї самої сторінки можна отримати доступ через декілька варіацій URL. Пропуск будь-якої варіації означає зламані посилання та втрату трафіку.
Критичні варіації URL
| Тип варіації |
Приклад A |
Приклад B |
| www проти non-www |
www.example.com/page |
example.com/page |
| Кінцевий слеш |
/products/ |
/products |
| Використання великих літер |
/Products/Widget |
/products/widget |
| Кодування URL |
/search?q=hello%20world |
/search?q=hello world |
| Протокол |
https:// |
http:// |
| Індексні файли |
/folder/index.html |
/folder/ |
Як варіації викликають проблеми
Зовнішні посилання та закладки можуть використовувати будь-яку варіацію:
Зворотне посилання використовує: example.com/Blog/Post-Title
Ваш редирект: www.example.com/blog/post-title
Результат: помилка 404, редирект не збігається
Збір всіх варіацій
- Перевірте звіти про зворотні посилання: Зовнішні сайти використовують непослідовні формати
- Перегляньте логи сервера: Перегляньте фактичні запитувані URL
- Тестуйте вручну: Спробуйте поширені варіації важливих сторінок
- Search Console: Показує варіації URL, з якими стикався Google
Стратегія стандартизації
Визначте свій канонічний формат, а потім перенаправте всі варіації:
| Старий шлях |
Перенаправити до |
| /Products/ |
/products |
| /PRODUCTS/ |
/products |
| /products |
/products |
| /Products |
/products |
Використовуйте співставлення без урахування регістру, якщо ваша платформа це підтримує. Інакше створюйте редиректи для всіх відомих варіацій регістру високотрафікових URL.
Як мені зібрати URL із зворотними посиланнями?
Збережіть SEO-капітал
URL з зовнішніми зворотними посиланнями несуть SEO-цінність, яка передається через 301 редиректи. Інструменти аналізу зворотних посилань виявляють, які URL мають цей капітал.
Поширені інструменти зворотних посилань
| Інструмент |
Ключова функція |
| Ahrefs |
Site Explorer → Best by Links |
| Semrush |
Backlink Analytics → Indexed Pages |
Процес експорту (загальні кроки)
- Введіть свій домен у функцію аналізу сайту інструменту
- Перейдіть до звіту про сторінки або URL (показує, які сторінки отримують зворотні посилання)
- Експортуйте повний список сторінок зі зворотними посиланнями
- Відфільтруйте до URL лише вашого домену
Ключові точки даних для захоплення
| Точка даних |
Мета |
| Цільова URL |
URL, що отримує зворотні посилання |
| Реферальні домени |
Кількість унікальних сайтів, що посилаються |
| Загальна кількість зворотних посилань |
Загальна кількість посилань |
| Показник якості посилань |
Індикатор авторитетності (варіюється за інструментом) |
Структура пріоритизації
Не всі URL зі зворотними посиланнями рівноцінні:
| Реферальні домени |
Пріоритет |
Дія |
| 50+ |
Критичний |
Обов’язково перенаправити |
| 10-49 |
Високий |
Слід перенаправити |
| 2-9 |
Середній |
Перенаправити, якщо практично |
| 1 |
Низький |
Оцінити індивідуально |
Не забувайте про зворотні посилання на 404
Більшість інструментів зворотних посилань показують посилання, що вказують на URL, які повертають 404:
- Шукайте фільтр коду статусу або звіт зламаних зворотних посилань
- Відфільтруйте, щоб показати лише 404 URL
- Експортуйте ці URL (вони потребують редиректів, незважаючи на те, що зламані)
⚠️ Зворотні посилання на неіснуючі сторінки
Зовнішні сайти часто посилаються на URL, які більше не існують на вашому сайті. Ці 404 URL зі зворотними посиланнями слід перенаправити на найбільш релевантну існуючу сторінку, щоб захопити капітал посилань.
Експортуйте дані про зворотні посилання щомісяця під час планування міграції. Нові зворотні посилання з'являються регулярно, і ви хочете захопити їх усі перед запуском.
Навіщо мені сканувати XML-карту сайту?
Захоплення заявлених важливих URL
Ваша XML-карта сайту представляє URL, про які ви явно повідомили пошуковим системам як важливі. Вони всі повинні бути включені у ваше планування редиректів.
Що розкривають карти сайту
| Елемент карти сайту |
Використання при міграції |
| Список URL |
Сторінки, які ви вважаєте важливими |
| Дати останньої зміни |
Нещодавно оновлений контент |
| Значення пріоритету |
Ваша ієрархія контенту |
| Частота змін |
Шаблони оновлення контенту |
Витягування URL карти сайту
Метод 1: Пряме завантаження
https://example.com/sitemap.xml
https://example.com/sitemap_index.xml
Метод 2: Screaming Frog
- Mode → List
- Upload → Download Sitemap
- Введіть URL карти сайту
- Сканування для перевірки URL
Метод 3: Search Console
- Звіт про карти сайту показує подані URL
- Покриття індексу показує, які проіндексовані
Порівняння карти сайту та сканування
Порівняйте URL вашої карти сайту з результатами сканування:
| Сценарій |
Значення |
Дія |
| У карті сайту, знайдено при скануванні |
Нормально |
Включити в редиректи |
| У карті сайту, не знайдено при скануванні |
Сторінка-сирота |
Перевірити існування сторінки, включити |
| При скануванні, не в карті сайту |
Відсутня в карті сайту |
Включити в редиректи |
Якщо ваша карта сайту автоматично генерується вашою CMS, вона може бути актуальнішою, ніж сканування. Завжди збирайте обидва та видаляйте дублікати.
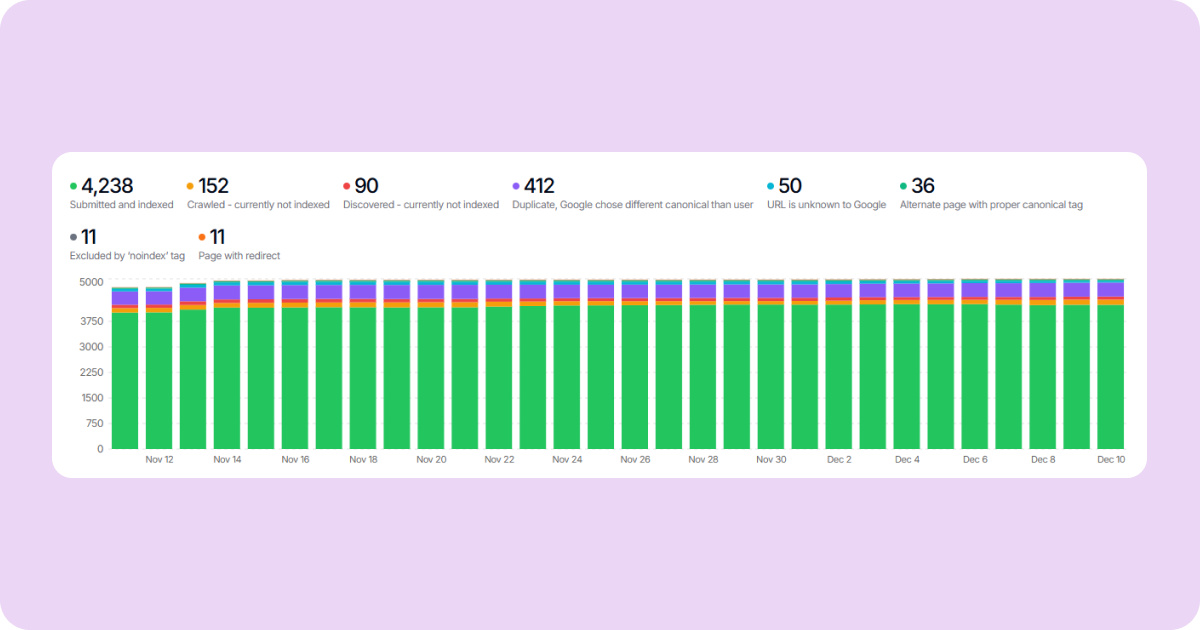
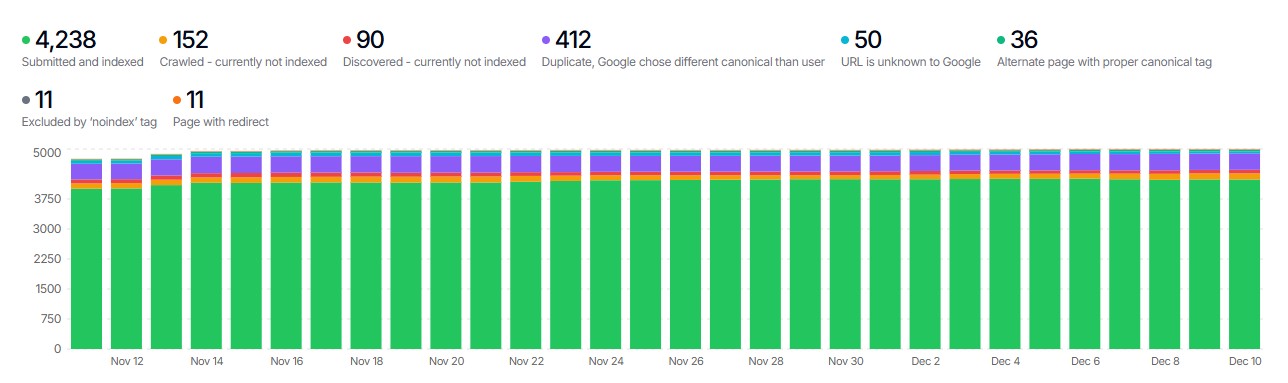
Як мені експортувати URL з Google Search Console?
Дізнайтеся, що знає Google
Google Search Console виявляє URL, які Google виявив і проіндексував, незалежно від того, чи з’являються вони у вашому скануванні або карті сайту.
Експорт даних URL
Зі звіту про покриття:
- Перейдіть до Indexing → Pages
- Клацніть кожну категорію статусу (Valid, Excluded тощо)
- Експортуйте список URL для кожної категорії
Зі звіту про продуктивність:
- Перейдіть до Performance
- Клацніть вкладку Pages
- Експортуйте, щоб побачити URL з враженнями/кліками
Категорії покриття для експорту
| Категорія |
Чому це важливо |
| Valid (Indexed) |
URL, що з’являються в результатах пошуку |
| Valid with warnings |
Проіндексовані, але мають проблеми |
| Excluded - Crawled not indexed |
Google знайшов, але не проіндексував |
| Excluded - Discovered not indexed |
Google знає про них, але не сканував |
| Excluded - Redirect |
URL, які Google бачить як перенаправлені |
Цінність даних продуктивності
URL з пошуковими враженнями або кліками є доведено цінними:
- Користувачі знаходять їх через пошук
- Google вважає їх релевантними для запитів
- Втрата цих URL означає втрату трафіку
Експортуйте дані за останні 16 місяців для найповнішої картини.
⚠️ Обмеження URL у Search Console
Експорти Search Console обмежені 1000 рядками в інтерфейсі. Використовуйте API Search Console або масовий експорт даних Google (BigQuery) для повних даних на великих сайтах.
Приділіть особливу увагу категорії "Excluded - Redirect". Вони показують редиректи, які Google вже виявив. Переконайтеся, що вони враховані у вашому новому плані редиректів.
Рекомендований інструмент: SEOGets
Для більш потужного способу роботи з даними Search Console розгляньте використання SEOGets. Їх звіт про індексацію надає більш складний вигляд ваших проіндексованих сторінок, ніж рідний інтерфейс Search Console, що полегшує виявлення та експорт URL, які вам потрібні для планування редиректів.
Як мені зібрати URL з аналітики?
Визначте сторінки, що генерують трафік
Дані аналітики показують, які URL фактично отримують трафік відвідувачів. Це ваші найвищепріоритетні кандидати на редиректи.
Експорт з Google Analytics (GA4)
- Перейдіть до Reports → Engagement → Pages and screens
- Встановіть діапазон дат на останні 12-16 місяців
- Експортуйте повний звіт про шлях сторінки
Ключові показники для захоплення
| Показник |
Індикатор пріоритету |
| Сесії |
Загальний обсяг трафіку |
| Користувачі |
Кількість унікальних відвідувачів |
| Рівень залученості |
Сигнал якості контенту |
| Конверсії |
Бізнес-цінність |
Створення рівнів пріоритету
Сегментуйте URL за обсягом трафіку:
| Місячні сесії |
Пріоритет |
Обробка редиректа |
| 1000+ |
Критичний |
Обов’язково перенаправити, перевірити призначення |
| 100-999 |
Високий |
Обов’язково перенаправити |
| 10-99 |
Середній |
Слід перенаправити |
| 1-9 |
Низький |
Перенаправити, якщо практично |
| 0 |
Найнижчий |
Перенаправляти лише якщо існують зворотні посилання |
Не забувайте про цільові сторінки
Фільтруйте сторінки, через які користувачі входять на ваш сайт:
- Вони часто пов’язані зовні або додані до закладок
- Втрата цільових сторінок має надмірний вплив на трафік
- Надавайте пріоритет редиректам для топових цільових сторінок
Порівняйте URL аналітики з вашим скануванням. Сторінки з трафіком, які не були знайдені при скануванні, можуть бути сиротами контенту, які все ще потребують редиректів.
Де мені знайти існуючі таблиці 301 редиректів?
Запобігання ланцюжкам редиректів
Перед створенням нових редиректів ви повинні знати, які редиректи вже існують. Ігнорування існуючих редиректів створює ланцюжки, які шкодять SEO та продуктивності.
Поширені джерела редиректів
| Джерело |
Де знайти |
Метод експорту |
| Адмін-панель CMS |
WordPress, Shopify тощо адмін-панель |
Вбудований експорт або запит до бази даних |
| Плагіни редиректів |
Yoast, Redirection, Rank Math |
Налаштування плагіна → Експорт |
| Периферійні сервіси |
Cloudflare, Fastly, Netlify |
Панель керування → Правила → Експорт |
| Мережеві платформи |
Балансувальники навантаження, CDN |
Конфігураційні файли |
| Конфігурація сервера |
.htaccess, nginx.conf |
Прямий доступ до файлу |
Місця, специфічні для CMS
WordPress:
- Плагін Redirection: Tools → Redirection → Export
- Yoast Premium: SEO → Redirects → Export
- База даних: таблиця
wp_redirection_items
Shopify:
- Admin → Content → URL Redirects → Export
Webflow:
- Site Settings → Publishing → 301 Redirects
Що документувати
Для кожного існуючого редиректу захопіть:
| Поле |
Приклад |
| Вихідна URL |
/old-page |
| URL призначення |
/new-page |
| Тип редиректу |
301 або 302 |
| Розташування |
Плагін, .htaccess, CDN |
| Дата створення |
2024-03-15 |
⚠️ Множинні джерела редиректів
Багато сайтів мають редиректи, налаштовані в кількох місцях (CMS, плагіни, сервер, CDN). Перевірте ВСІ джерела, щоб отримати повну картину. Пропуск одного джерела може викликати неочікувану поведінку редиректів.
Об'єднайте всі існуючі редиректи в єдиний документ перед міграцією. Це стає вашим довідником для того, що вже оброблено, і що може конфліктувати з новими редиректами.
Як корисно використовувати дані про ланцюжки редиректів?
Очистіть перед міграцією
Ланцюжки редиректів виникають, коли один редирект вказує на інший редирект, створюючи кілька переходів. Вони шкодять SEO та швидкості сторінки. Міграція — ідеальний час для їх усунення.
Виявлення ланцюжків редиректів
У Screaming Frog:
- Скануйте свій сайт
- Відфільтруйте за Status Code → 3xx
- Шукайте редиректи, де Redirect URL також є редиректом
Приклад ланцюжка:
/page-a → 301 → /page-b → 301 → /page-c → 200
Це ланцюжок з 2 переходами, який повинен стати:
/page-a → 301 → /page-c
/page-b → 301 → /page-c
Процес вирішення ланцюжка
- Складіть карту всіх ланцюжків редиректів: Документуйте кожен шаблон A→B→C
- Визначте кінцеві пункти призначення: Знайдіть, куди кожен ланцюжок зрештою веде
- Оновіть вихідні редиректи: Вкажіть безпосередньо на кінцеве призначення
- Видаліть проміжні редиректи: Видаліть непотрібні переходи
- Перевірте вирішення: Перевірте, що ланцюжки усунені
Поширені сценарії ланцюжків
| Сценарій |
До |
Після |
| HTTP до HTTPS до сторінки |
http→https→/new |
http→/new (якщо HTTPS застосовується на сервері) |
| Старий редирект + новий редирект |
/old→/middle→/new |
/old→/new, /middle→/new |
| Ланцюжок нормалізації WWW |
non-www→www→/page |
non-www→/page (www на рівні DNS) |
⚠️ Ланцюжки витрачають бюджет сканування
Боти пошукових систем можуть не слідувати за довгими ланцюжками редиректів, що означає, що сторінки в кінці ланцюжків можуть не бути належним чином просканованими або проіндексованими. Google рекомендує максимум 2 переходи.
Використовуйте дані існуючої таблиці редиректів для складання карти всіх ланцюжків перед створенням нових редиректів. Оновіть свій основний список редиректів, щоб кожна вихідна URL вказувала безпосередньо на своє кінцеве призначення на новому сайті.
Як створити єдиний набір даних URL?
Критичний заключний крок
Після збору URL з усіх джерел об’єднайте їх у єдиний набір даних без дублікатів. Це стає вашим основним списком джерел редиректів.
Процес об’єднання
Крок 1: Стандартизуйте формати
- Видаліть протоколи (
https://)
- Видаліть домени (
www.example.com)
- Стандартизуйте кінцеві слеші
- Конвертуйте в нижній регістр (якщо ваш сайт нечутливий до регістру)
Крок 2: Перевірте через Screaming Frog
Пропустіть кожен список URL через Screaming Frog в режимі списку:
- Mode → List
- Завантажте свій список URL
- Почніть сканування для перевірки кожної URL
- Експортуйте результати з кодами статусу
Це підтверджує поточний статус кожної URL у всіх джерелах.
Крок 3: Об’єднайте та видаліть дублікати
Джерело A: 5000 URL
Джерело B: 3500 URL
Джерело C: 8200 URL
Джерело D: 2100 URL
─────────────────────
Об'єднано: 18800 URL
Після видалення дублікатів: 12400 унікальних URL
Крок 4: Збагатіть метаданими
Додайте стовпці з кожного джерела:
| URL |
Статус |
Зворотні посилання |
Сесії |
У карті сайту |
Має редирект |
| /page-a |
200 |
45 |
1200 |
Так |
Ні |
| /page-b |
404 |
12 |
0 |
Ні |
Ні |
| /page-c |
301 |
8 |
340 |
Так |
Так |
Зберігайте свій об'єднаний набір даних у електронній таблиці з контролем версій або базі даних. Ви будете посилатися на нього та оновлювати протягом усього процесу міграції.
Готові зіставити свої URL?
Після того, як ви зібрали URL з усіх джерел і створили свій об’єднаний набір даних, наступним кроком є зіставлення старих URL з новими призначеннями. Якщо ви робили роботу з редиректами раніше, ви знаєте, що це традиційно найбільш трудомістка частина роботи з редиректами, але це не обов’язково має бути так.
Redirects.net використовує інтелектуальні алгоритми співставлення для автоматичного зіставлення ваших старих URL з найкращими призначеннями на вашому новому сайті. Завантажте свій об’єднаний список URL і отримайте зіставлені редиректи, готові до впровадження.
Спробуйте Redirects.net безкоштовно →